Ready
You are running a factory with 5,000 sensors reporting temperature, vibration, pressure, and throughput every second.
That is 430 million events per day. And right now, most teams are paying to ship every one of them — raw — to a cloud region hundreds of miles away before anything useful happens.
It works. Until it doesn’t.
The first sign is the cloud bill. Then it’s the latency. Then it’s the outage at a remote site that takes down local operations because a central service went unreachable. By the time the architecture is obviously broken, you are already mid-incident.
This post is about the architecture that prevents that — and why it is becoming the default for teams running distributed systems at scale.
The Bandwidth Math Nobody Does Until It’s Too Late
Let’s make this concrete. Assume each sensor update is about 500 bytes after protocol overhead.
- 5,000 sensors × 1 update/sec = 5,000 messages/sec
- 5,000 × 500 bytes = 2,500,000 bytes/sec (about 2.5 MB/s)
- 2.5 MB/s sustained = about 20 Mbps
- Per day: about 216 GB
- Per 30-day month: about 6.5 TB from one site
If your events are closer to 1 KB — which they often are once you factor in metadata — that’s 13 TB/month from a single site.
That is raw telemetry only. Add retries, reconnect bursts, backfills, and duplicate streams for analytics and alerting, and the number grows further.

Most of that data is noise. Routine readings within normal range. Nothing actionable. You are paying to move it, store it, and index it — and then mostly ignoring it.
The Deeper Problem: Decision Distance
Bandwidth cost is painful but survivable. The failure mode that actually breaks systems is something different: decision distance.
Decision distance is the gap between where data is produced and where the decision gets made. In a cloud-only architecture, that gap is measured in network hops and queue delays. When everything is fine, that gap is invisible. When something goes wrong, it becomes the reason the system failed to respond in time.
A machine detects a dangerous vibration pattern. You need it stopped in milliseconds. But in a cloud-only system, the signal has to travel out, wait in a processing queue, get evaluated, and send a command back. The decision arrives after the damage.
This compounds as systems grow:
- Latency becomes unpredictable — and unpredictable latency in operational systems means unpredictable outcomes.
- Network outages become site outages — a flaky WAN link shouldn’t shut down a production line, but in a cloud-dependent architecture it often does.
- Central services become single points of failure — the more sites you run, the harder the blast radius when a central service has a bad day.
The answer is not to abandon the cloud. It is to stop routing every decision through it.
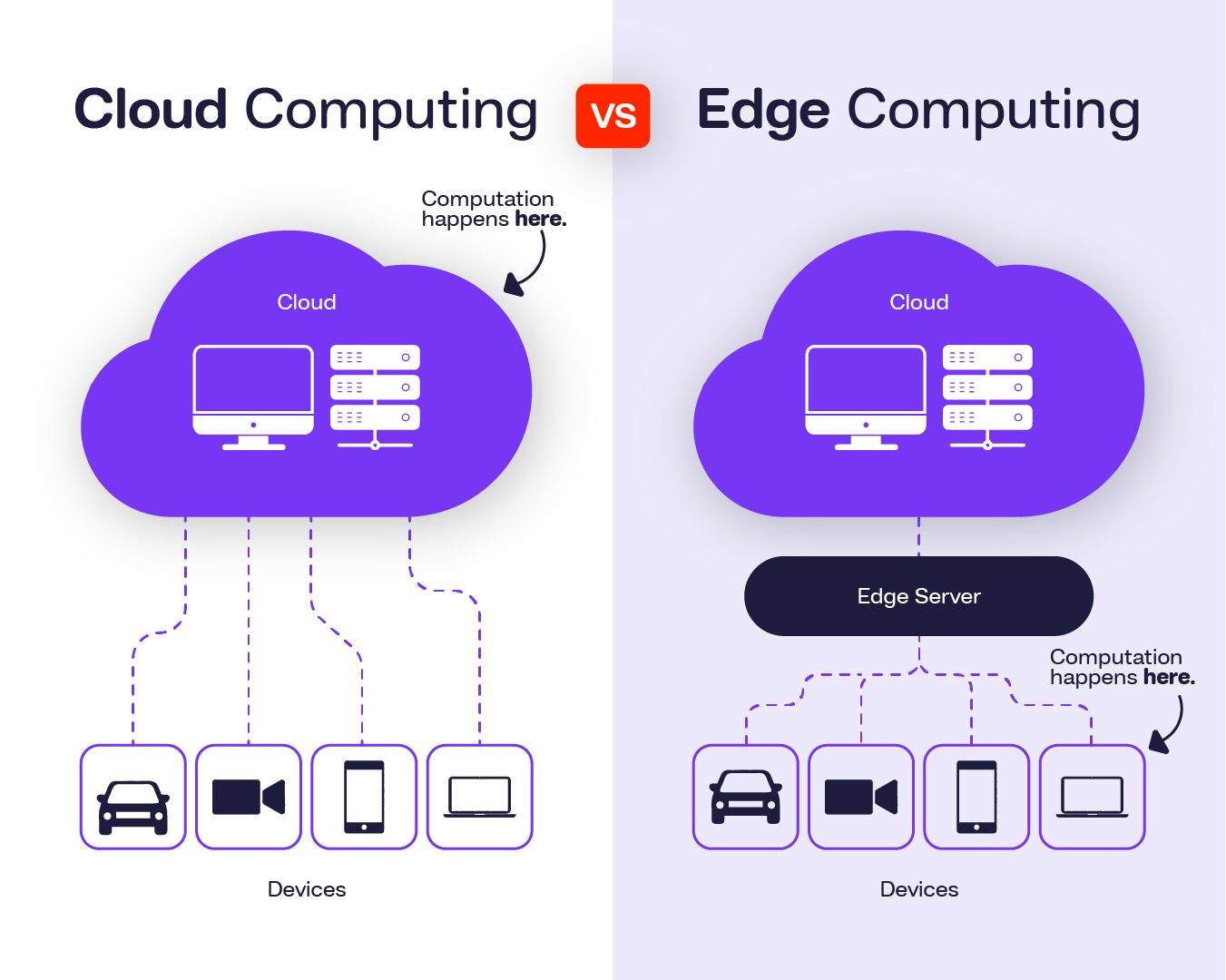
From Cloud to Edge to Cloud-Edge Computing
To understand how this gets fixed, it helps to be precise about the terms.
1. Cloud Computing
Cloud computing centralizes processing, storage, and networking in remote data centers operated by providers such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud. The cloud excels at things that benefit from scale and centralization:
- Large-scale analytics
- Machine learning workloads
- Centralized coordination across distributed assets
- Long-term storage and historical data processing
The cloud model is built on elasticity, abstraction, and global accessibility, as formalized in the NIST definition of cloud computing.
The limitation: cloud computing assumes reliable connectivity and acceptable network latency. For operational technology (OT), industrial systems, and anything requiring real-time response, round-trip delays to a distant data center are not a performance concern — they are an architectural constraint.
2. Edge Computing
Edge computing moves computation closer to where data is generated — near machines, sensors, users, or industrial systems. Instead of transmitting raw data to centralized infrastructure, edge systems process and decide locally. This is described in foundational work such as Shi et al., Edge Computing: Vision and Challenges (IEEE Internet of Things Journal, 2016).
Edge computing enables:
- Low-latency decisions — sub-100ms response times that cloud routing cannot match
- Real-time control loops — feedback cycles that depend on local processing
- Resilience to connectivity loss — sites that keep operating when the WAN link is unstable
- Local filtering — only meaningful data leaves the site
Edge computing typically spans two layers:
- Site-level edge: On-premise compute in factories, hospitals, energy plants, and similar environments
- Far edge: Embedded controllers and constrained devices that need deterministic, immediate local action
3. Cloud-Edge Computing
Cloud-edge computing is not a replacement for the cloud. It is a placement strategy.
Each workload runs where it makes the most operational sense. As defined by organizations such as the Linux Foundation Edge and ETSI Multi-access Edge Computing (MEC):
- Cloud: heavy analytics, fleet-wide coordination, model training, long-term storage
- Edge: latency-sensitive decisions, local aggregation, real-time control
- Far edge: deterministic control and immediate actuation
The cloud stays at the center of the architecture. It just stops being the path every decision has to travel through.
How Data Moves in a Cloud-Edge System
In practice, cloud-edge architectures run two traffic flows that look very different from each other.
Upstream: From Device to Platform
Edge systems filter, aggregate, and prioritize. Only high-value data — anomalies, summaries, events — travels to the cloud. Routine readings that fall within normal range are processed and discarded at the edge.
The cloud receives a distilled signal, not a raw stream, and uses it for cross-site analytics, model training, global optimization, and archiving. This model is central to industrial IoT architectures described by the Industrial Internet Consortium.
Downstream: From Platform to Device
Latency-sensitive responses — control commands, model updates, configuration changes — go directly to edge nodes rather than bouncing through a central processing path. This is the same approach companies like Cloudflare use for content delivery: keep the response path short.
Common Implementation Patterns
Cloud-edge systems are typically built from three building blocks:
- Site-level edge compute — on-premise servers or gateways adjacent to operational equipment, handling local processing and control
- Smarter endpoints — IoT devices with basic filtering logic, reducing transmission at the source
- Regional edge services — cloud-managed edge locations like AWS Wavelength or Azure Edge Zones that bring compute closer to users
These layers work hierarchically. Each layer reduces what the next layer has to handle.
Why This Is Becoming Urgent Now
Three forces are converging at the same time:
Data is growing at the edge, not in the cloud. Manufacturing, logistics, energy, and healthcare are generating more operational data closer to physical assets. The growth curve is not in data centers — it is at the site level.
Latency requirements are tightening. Robotics, predictive maintenance, energy grid management, and autonomous systems cannot tolerate variable round-trip delays to a distant cloud region. They need decisions in milliseconds, locally.
Regulators are mandating data locality. GDPR and equivalent frameworks in other regions increasingly require that certain data be processed within specific jurisdictions. A cloud-only architecture that centralizes everything in one region is not always compliant.
Cloud-edge architecture addresses all three without sacrificing scalability. Teams that get this right gain real operational advantages:
- Lower latency: critical decisions happen at the edge, in near real time
- Lower costs: only meaningful data is transported and stored centrally
- Better resilience: sites continue operating when internet links are unstable
- Stronger data control: sensitive data stays local; only approved outputs leave
- Faster feedback loops: operators get better signal faster, which improves every downstream decision
The Part Nobody Talks About: Actually Running It
Understanding the model is the easy part. Running distributed systems across cloud, edge gateways, and constrained devices is genuinely hard.
- Hardware is heterogeneous — different CPUs, operating systems, memory constraints
- Connectivity is unreliable — remote sites have intermittent or bandwidth-constrained links
- Deployment is complex — updating logic on dozens of edge devices is not like deploying to a cloud VM
- Security surface is larger — more nodes means more exposure
- Observability is harder — you cannot just SSH into every site and check logs
This is where most cloud-edge implementations struggle. The architecture is sound in principle; the operational burden is what breaks teams in practice.
Why WebAssembly Changes the Equation
WebAssembly (Wasm) addresses the heterogeneity problem directly:
- The same binary runs on any supported platform — one artifact, many edge targets
- Sandboxed execution — isolation without a full container runtime
- Fast startup — no VM boot, no container initialization
- Small footprint — Wasm artifacts are often significantly smaller than equivalent container images
- Language agnostic — compile from Rust, Go, C/C++, and others
Wasm does not solve orchestration. But it eliminates one of the hardest parts: making the same workload portable across a fleet of heterogeneous edge hardware.
How Propeller Solves the Orchestration Problem
Most teams building cloud-edge systems end up managing two separate stacks — one for the cloud, one for the edge — with no unified control plane between them. Every deployment involves SSH sessions, manual file transfers, and coordination calls with site operations teams.
Propeller eliminates that gap. It is an open-source orchestrator built specifically for Wasm workloads across the cloud-edge continuum.
It handles:
- Task scheduling and placement — the right workload runs on the right proplet automatically
- Distributed execution — proplets at edge sites run tasks without any inbound network access required
- Registry-based delivery — Wasm binaries are pulled from OCI registries and streamed to proplets automatically
- Centralized observability — metrics, task state, and results are queryable from one place regardless of where the proplet runs
- Full lifecycle management — create, start, stop, update, and monitor tasks through a consistent API and CLI
You focus on writing workload logic. Propeller handles where it runs and how it gets there.
Architecture: Manager in the Cloud, Proplets at the Edge
Propeller’s architecture maps cleanly onto the cloud-edge model.
The Manager runs centrally — in your cloud environment or a central on-premise server. It handles scheduling, proplet discovery, result storage, and metrics aggregation. All interaction with the system goes through the Manager. Edge devices never need to be directly reachable.
The Manager runs centrally — on a gateway, industrial PC, or any Linux machine. They register with the Manager at startup, listen for task commands, execute Wasm binaries using the Wasmtime runtime, and report results back. Proplets need only outbound MQTT connectivity. No open firewall rules. No VPN. No inbound ports.
SuperMQ is the MQTT broker layer connecting them. All control messages — task dispatches, results, heartbeats, binary chunks — flow through it. Edge sites behind firewalls or on intermittent links can participate as long as they can reach the broker.
The Proxy handles OCI registry delivery. When a task references a container image, the proxy fetches the Wasm binary, chunks it, and streams it to the proplet over MQTT. Proplets do not need direct internet access to receive new workloads.
The result: a task submitted from a laptop in one country can run on edge hardware at a remote factory on another continent — without VPN, without direct network access, without any manual steps at the site.
What This Looks Like in Practice
Industrial IoT
A vibration filter deployed to a factory proplet runs under 4% average CPU and less than 23 MB of memory — comparable to a native binary — with full Wasm sandboxing. It processes sensor readings locally and forwards only anomaly events, reducing outbound bandwidth by roughly 97% compared to streaming raw data to the cloud.
When a better detection model is ready, the operator stops the running task through the Manager and starts a new one pointing at the updated image. No site visit. No maintenance window. No SSH. The proplet fetches and runs the new binary automatically.
Smart Infrastructure
Intersection proplets across a city run the same traffic signal logic, each configured with zone-specific parameters — peak hours, capacity thresholds — applied at dispatch time. Tasks run in parallel across all sites and complete within seconds of each other. Individual decisions happen entirely at the edge. Aggregated traffic and congestion data flow to the cloud for city-level planning.
Healthcare Sites
A diagnostic inference task runs inside a hospital’s private network. The Wasm module receives inputs, produces a classification with a confidence score, and only that result travels upstream. The raw imaging data stays on-site. Data residency compliance is enforced by the architecture, not a policy document.
Propeller in Action: Predictive Maintenance at the Edge
Consider a factory running vibration sensors on its production line. The goal: detect anomalies locally, in near real time, and send only actionable events upstream.
The detection logic is packaged as a Wasm module and pushed to a container registry. Deploying it to the edge is a single operation through the Manager. Propeller assigns the task to the proplet running on the factory gateway and streams the binary over MQTT. No SSH session. No file transfer. No access to the factory network required.
Once running, a check on a sensor reading completes in under 100 milliseconds end to end — the Manager dispatches, the proplet executes on the edge hardware, and the result is returned. The decision never left the factory floor.
When a better model is available, the operator stops the current task and starts a new one pointing at the updated image. The proplet fetches the new binary and resumes. No maintenance window. No coordination call with the site team.
For more complex workflows, Propeller supports chaining tasks with explicit dependencies. A post-detection summarization step runs only when detection succeeds. An alerting step fires only when it fails. The Manager enforces execution order and conditional logic. Teams write business logic; Propeller handles the rest.
Centralized Visibility Across Every Edge Site
One of the most underestimated operational problems in cloud-edge systems is monitoring. You cannot SSH into a hundred edge gateways to check on running processes. You need a single point of truth.
Propeller collects CPU usage, memory consumption, disk I/O, and uptime from every running task and surfaces it through the Manager — no agents, no VPN, no direct machine access. Configure a collection interval and retain a rolling history of samples per task.
Metrics can also be streamed in real time to any MQTT subscriber, making it straightforward to feed existing dashboards or alerting pipelines without any custom integration work.
Scheduled and Federated Workloads
Recurring Tasks, Without a Cron Daemon
Tasks that run on a schedule — hourly summaries, daily evaluations, periodic calibrations — are configured with a standard cron expression and timezone. Propeller’s Manager handles the schedule and dispatches the task at each interval. No cron daemon on the edge device. No manual trigger between runs.
Federated Learning Across Sites
Federated learning is where the cloud-edge model becomes especially powerful. Each site trains a model on its own data. Only model weight updates — not raw data — travel to the cloud for aggregation.
Propeller orchestrates this natively. Specify the participating proplets, a reference to the global model, and training hyperparameters. Propeller dispatches a Wasm training task to each participant. Each proplet trains locally and sends updates to the FL coordinator. When a configured quorum of updates arrives, the coordinator aggregates them and stores a new model version.
A continuously improving shared model, across dozens of sites, with no raw data crossing a single network boundary. For multi-tenant deployments where data sharing between sites is contractually or legally prohibited, this is not a workaround — it is the intended architecture.
When Cloud-Edge Is Worth the Investment
Cloud-edge pays off most clearly when you have:
- Latency-sensitive actions where a cloud round-trip is too slow
- High telemetry volume where transporting raw data is expensive
- Multiple remote sites with inconsistent connectivity
- Intermittent links that should not take down local operations
- Data residency requirements that restrict where processing can happen
If your workload is batch-oriented, centrally located, and has no real-time requirements, the cloud alone is probably sufficient. Cloud-edge is not always the answer — but when it is, the operational and cost difference is significant.
A Migration Approach That Actually Works
The biggest mistake teams make is trying to redesign everything at once. That path leads to long timelines, scope creep, and systems that are half-migrated when they ship.
A more reliable approach:
- Pick one workflow — latency-sensitive, data-heavy, ideally with a clear cost or reliability problem today
- Move that one path to edge execution, leaving everything else unchanged
- Measure before and after — latency, bandwidth consumption, failure impact, and cost
- Expand incrementally based on what the data shows

The goal is not a perfect architecture from day one. It is a system you can improve safely, with evidence at every step.
Ready to See It Running?
Cloud-edge computing is not anti-cloud. It is architecture discipline — keeping urgent decisions close to where data is produced, and reserving the cloud for what it actually does well.
Propeller makes that split practical. You write Wasm workloads. Propeller handles placement, delivery, execution, and observability — across cloud and edge, from a single control plane.
Propeller is open source. You can run the full stack locally, connect proplets, and deploy your first Wasm task in minutes.
→ Explore the documentation and get started at propeller.absmach.eu